
Banco de Dados Relacional
Este é o material teórico utilizado nas aulas de Banco de Dados que eu ministrei aos meus colegas de trabalho em 2021-2022. O material original está em slides de Power Point, por isso o conteúdo está basicamente todo em bullet points.
O objetivo do treinamento foi reforçar a compreensão dos fundamentos de Banco de Dados Relacional por meio de aprendizado prático e aplicado.
O que é um banco de dados relacional?
Segundo a Oracle:
- Um banco de dados relacional é um tipo de banco de dados que armazena e fornece acesso a pontos de dados relacionados entre si.
- Bancos de dados relacionais são baseados no modelo relacional, uma maneira intuitiva e direta de representar dados em tabelas.
- Em um banco de dados relacional, cada linha na tabela é um registro com um ID exclusivo chamado chave.
- As colunas da tabela contêm atributos dos dados e cada registro geralmente tem um valor para cada atributo, facilitando o estabelecimento das relações entre os pontos de dados.
SGBD (Sistema de Gerenciamento de Banco de Dados)
Um banco de dados é geralmente controlado por um sistema de gerenciamento de banco de dados (SGBD) – ou Data Base Management System (DBMS), em inglês.
Um SGBD serve como uma interface entre o banco de dados e seus usuários finais ou programas, permitindo que os usuários recuperem, atualizem e gerenciem como as informações são organizadas e otimizadas.

Modelagem
A modelagem de dados é o processo de criação de um modelo de dados para que os dados sejam armazenados em um banco de dados. Esse modelo de dados é uma representação conceitual de objetos de dados, associações entre diferentes objetos de dados e as regras.
O modelo de dados é definido como um modelo abstrato que organiza a descrição dos dados, a semântica dos dados e as restrições de consistência dos dados. O modelo de dados enfatiza quais dados são necessários e como eles devem ser organizados, em vez de quais operações serão executadas nos dados.
Modelo Conceitual
Este modelo define O QUE o sistema contém. Este modelo geralmente é criado pelas partes interessadas (stakeholders) de negócios e pelos arquitetos de dados. O objetivo é organizar, delimitar e definir conceitos e regras de negócios.
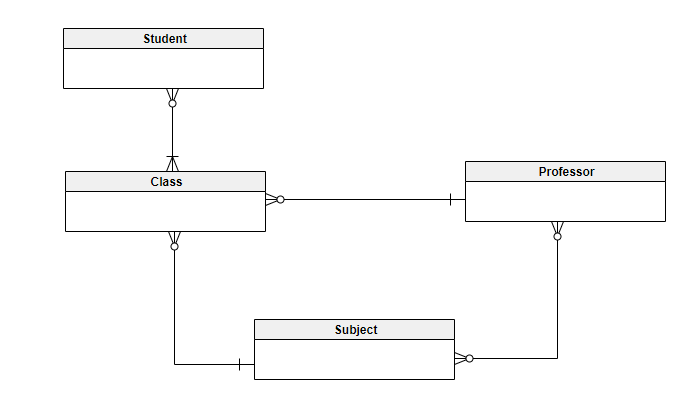
Modelo Lógico
Este modelo define COMO o sistema deve ser implementado, independentemente do SGBD. Este modelo é normalmente criado por arquitetos de dados e analistas de negócios. O objetivo é desenvolver o mapa técnico de regras e estruturas de dados.
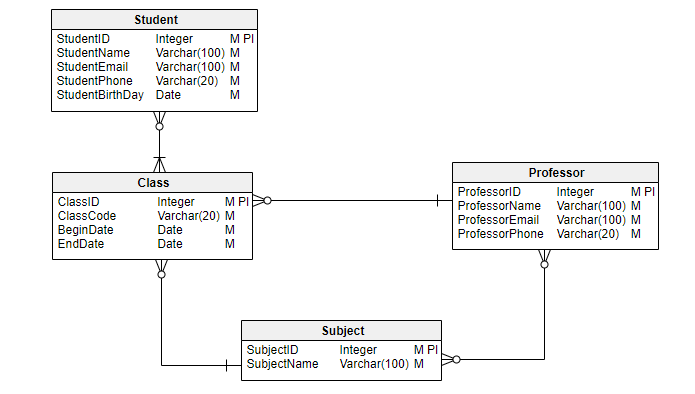
Modelo Físico
Este modelo descreve COMO o sistema será implementado usando um SGBD específico. Este modelo normalmente é criado pelo DBA (administrador do banco de dados) e desenvolvedores. O objetivo é a implementação real do banco de dados.
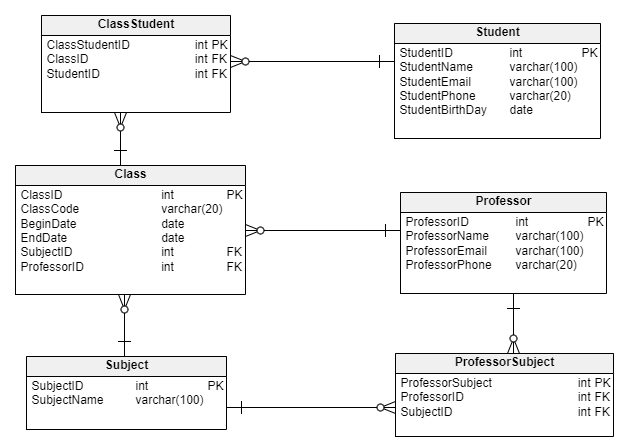
Relacionamentos entre entidades e cardinalidade
Relacionamento 1:1 (One-to-One)
No relacionamento Um-para-Um, um registro da primeira tabela será vinculado a zero ou a um registro de outra tabela.
Por exemplo, cada funcionário na tabela Employee terá uma linha correspondente na tabela EmployeeDetails, que armazena os detalhes atuais do passaporte desse funcionário específico.
Assim, cada funcionário terá zero ou um registro na tabela EmployeeDetails.
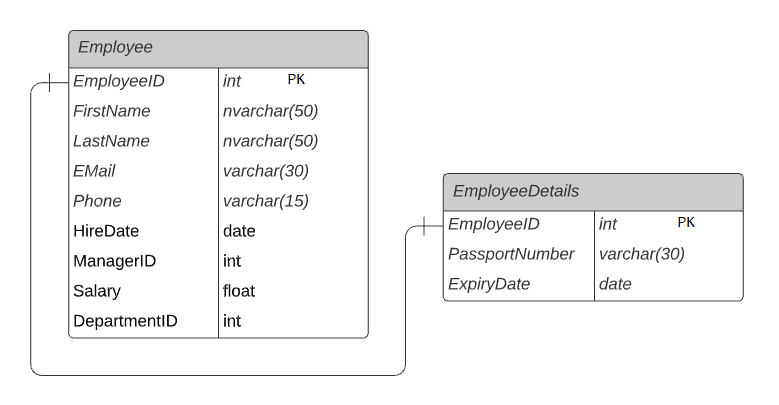
A coluna EmployeeID é a chave primária (Employee) e chave primária e estrangeira (EmployeeDetails). Isso forma uma relação zero (pois é opcional) ou um-para-um.
Relacionamentos 1:n (One to Many) e n:1 (Many to One)
Um-para-Muitos é o relacionamento mais comum usado entre tabelas. Um único registro de uma tabela pode ser vinculado a zero ou mais linhas em outra tabela.
Por exemplo, a tabela Employee armazena registros de funcionários em que EmployeeID é a chave primária. A tabela Address contém os endereços dos funcionários onde AddressID é uma chave primária e EmployeeID é uma chave estrangeira.
Cada funcionário terá um registro na tabela Employee. Cada funcionário pode ter vários endereços, como endereço residencial, endereço do escritório, endereço permanente, etc.

As tabelas Employee e Address são vinculadas pela coluna de chave EmployeeID. É uma chave estrangeira na tabela de endereços vinculada à chave primária EmployeeID na tabela de funcionários. Assim, um registro da tabela Employee pode apontar para vários registros na tabela Address. Esse é um relacionamento de um para muitos.
Relacionamento n:n (Many to Many)
O relacionamento Muitos-para-Muitos permite relacionar cada linha em uma tabela a muitas linhas em outra tabela e vice-versa.
Por exemplo, um funcionário na tabela Employee pode ter várias skills da tabela EmployeeSkill e também uma skill pode ser associada a um ou mais funcionários.
A figura a seguir demonstra a relação muitos-para-muitos entre a tabela Employee e SkillDescription usando a tabela de junção EmployeeSkill.
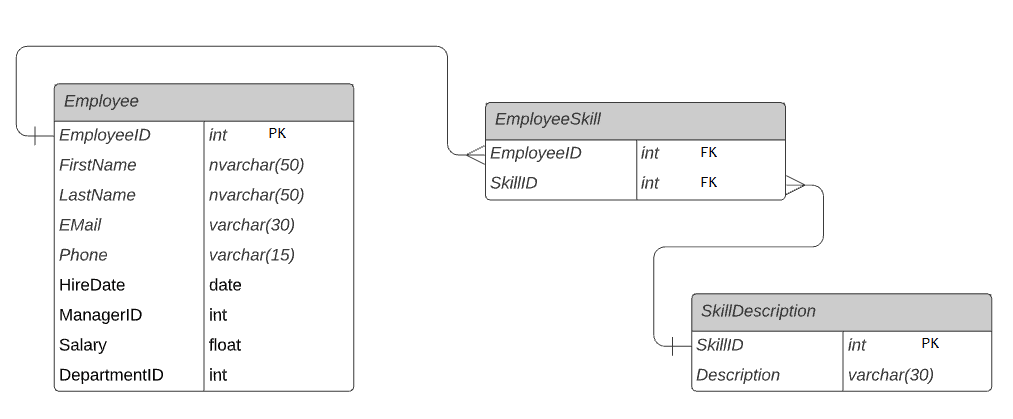
Cada funcionário na tabela Employee pode ter uma ou várias skills. Da mesma forma, uma skill na tabela SkillDescription pode ser vinculada a muitos funcionários. Isso cria uma relação de muitos para muitos.
No exemplo, EmployeeSkill é a tabela de junção que contém as colunas de chave estrangeira EmployeeID e SkillID para formar uma relação muitos-para-muitos entre a tabela Employee e SkillDescription.
Individualmente, Employee e EmployeeSkill têm uma relação um-para-muitos e as tabelas SkillDescription e EmployeeSkill têm uma relação um-para-muitos. Mas, eles formam uma relação muitos-para-muitos usando uma tabela intermediária EmployeeSkill.
Restrições e tipos de chaves (Key Constraints)
- PK: chave primária (Primary Key):
- Uma chave primária é usada para garantir que os dados na coluna específica sejam exclusivos. É uma coluna que não pode ter valores NULL. Seus valores podem ser gerados automaticamente de acordo com uma sequência definida.
- FK: chave estrangeira (Foreign Key)
- Uma chave estrangeira é uma coluna que fornece uma conexão entre os dados de duas tabelas. É uma coluna que faz referência a uma coluna (geralmente a chave primária) de outra tabela. Uma tabela pode ter várias FK.
- Chave primária composta (Composite Primary Key)
- Uma chave primária com dois ou mais atributos é chamada de chave composta. É uma combinação de duas ou mais colunas.
- UK: chave única (Unique Key)
- Uma chave única é uma coluna que identifica de forma exclusiva um registro em uma tabela. UK aceita NULL.
Tipos de dados
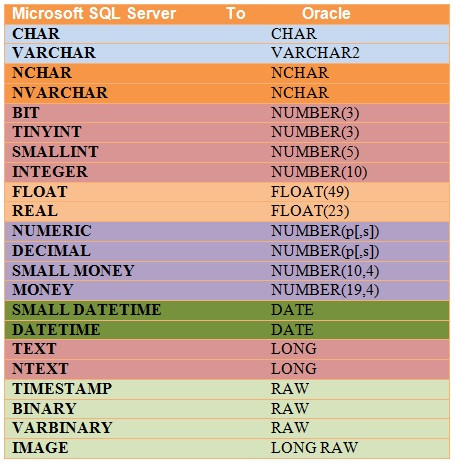
Os nomes podem mudar, dependendo do SGBD utilizado.
SQL (Structured Query Language)
SQL é uma linguagem projetada para a recuperação e o gerenciamento de dados em um banco de dados relacional. A SQL compreende alguns subconjuntos de comandos:
- DML (Data Manipulation Language): manipulação de dados
- incluir, alterar e excluir dados presentes em registros (INSERT, UPDATE e DELETE)
- DDL (Data Definition Language): definição de dados
- criar, derrubar e alterar tabelas e elementos associados (CREATE, DROP, ALTER)
- DQL (Data Query Language): consulta de dados
- consultar registros em uma ou mais tabelas (SELECT)
Cláusulas
As cláusulas são condições de modificação utilizadas para definir os dados que deseja selecionar ou modificar em uma consulta:
- FROM – Utilizada para especificar a tabela, que se vai selecionar os registros.
- WHERE – Utilizada para especificar as condições que devem reunir os registros que serão selecionados.
- GROUP BY – Utilizada para separar os registros selecionados em grupos específicos.
- HAVING – Utilizada para expressar a condição que deve satisfazer cada grupo.
- ORDER BY – Utilizada para ordenar os registros selecionados com uma ordem especifica.
- DISTINCT – Utilizada para selecionar dados sem repetição.
- UNION – Combina os resultados de duas consultas SQL em uma única tabela para todas as linhas correspondentes.
Operadores
- AND – E lógico. Avalia as condições e devolve um valor verdadeiro caso ambos sejam corretos.
- OR – OU lógico. Avalia as condições e devolve um valor verdadeiro se algum for correto.
- NOT – Negação lógica. Devolve o valor contrário da expressão.
- BETWEEN – Utilizado para especificar valores dentro de um intervalo fechado.
- LIKE – Utilizado na comparação de um modelo e para especificar registros de um banco de dados.
LIKE+ extensão%significa buscar todos resultados com o mesmo início da extensão. - IN – Utilizado para verificar se o valor procurado está dentro de uma lista. Ex.:
valor IN (1,2,3,4).
| < | Menor |
| > | Maior |
| <= | Menor ou igual |
| >= | Maior ou igual |
| = | Igual |
| <> | Diferente |
Funções
As funções mais comuns são:
- COUNT, SUM
- AVG, MIN, MAX
- ROWNUM
- LOWER, UPPER
- TRIM
- SYSDATE
Todas as funções listadas por categoria: Oracle Functions.
Juntando tabelas (JOIN e UNION)
| JOIN | UNION |
|---|---|
| Junta dados de várias tabelas com base em uma condição de correspondência entre elas. | Associa o conjunto de resultados de dois ou mais SELECTs. |
| Junta os dados em novas colunas. | Junta os dados em novas linhas. |
| O número de colunas selecionadas de cada tabela pode não ser o mesmo. | O número de colunas selecionadas de cada tabela deve ser o mesmo. |
| Os tipos de dados das colunas correspondentes selecionadas de cada tabela podem ser diferentes. | Os tipos de dados das colunas correspondentes selecionadas de cada tabela devem ser os mesmos. |
| Pode não retornar colunas distintas. | Retorna linhas distintas. |
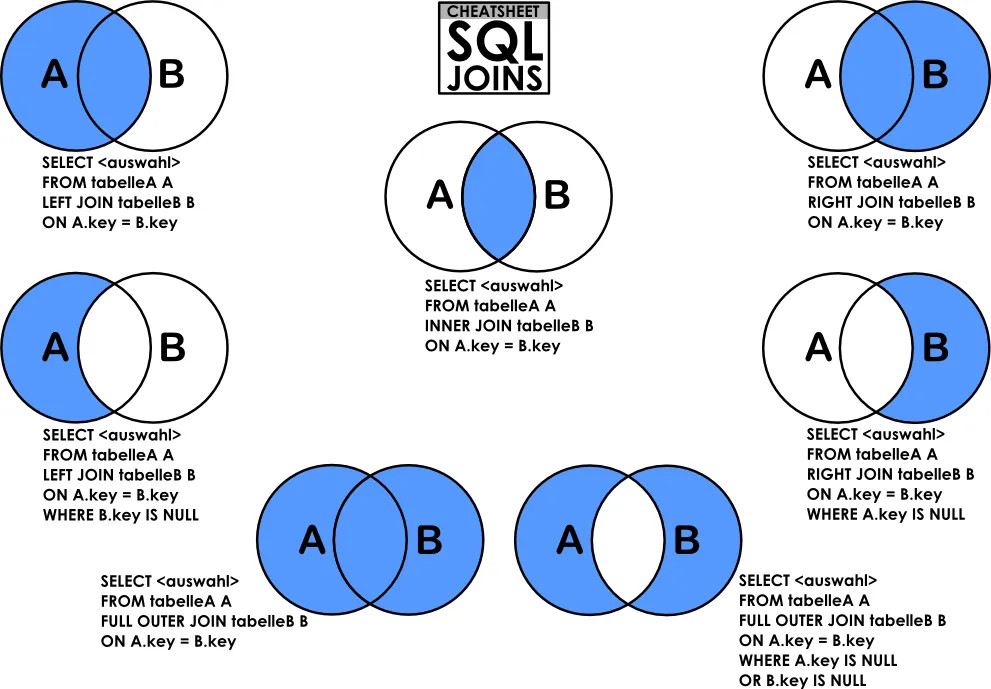
Tipos de JOIN
Fontes
- Oracle (O que é um Banco de Dados Relacional?)
- Oracle (O que é um banco de dados?)
- Guru99 (What is Data Modelling?)
- Vertabelo (What Are Conceptual, Logical, and Physical Data Models?)
- TutorialsTeacher (Tables Relations in SQL Server)
- GeeksforGeeks (Difference between Primary Key and Foreign Key)
- Wikipedia (SQL)
- Tech on the Net (Oracle Functions)
- GeeksforGeeks (Difference between JOIN and UNION in SQL)





